- Confidentiality. User uploads only (encrypted) executable not source code.
- No computation, no payment.
- Lease rather than buy. No upfront cost to buy expensive hardware. No maintenance cost.
- Support CPU as well as GPU.
- Suites of optimization algorithms to suit your needs.
Example
Parallel optimization for 7 MACD parameters. Using clusters, we can find best parameters significantly faster.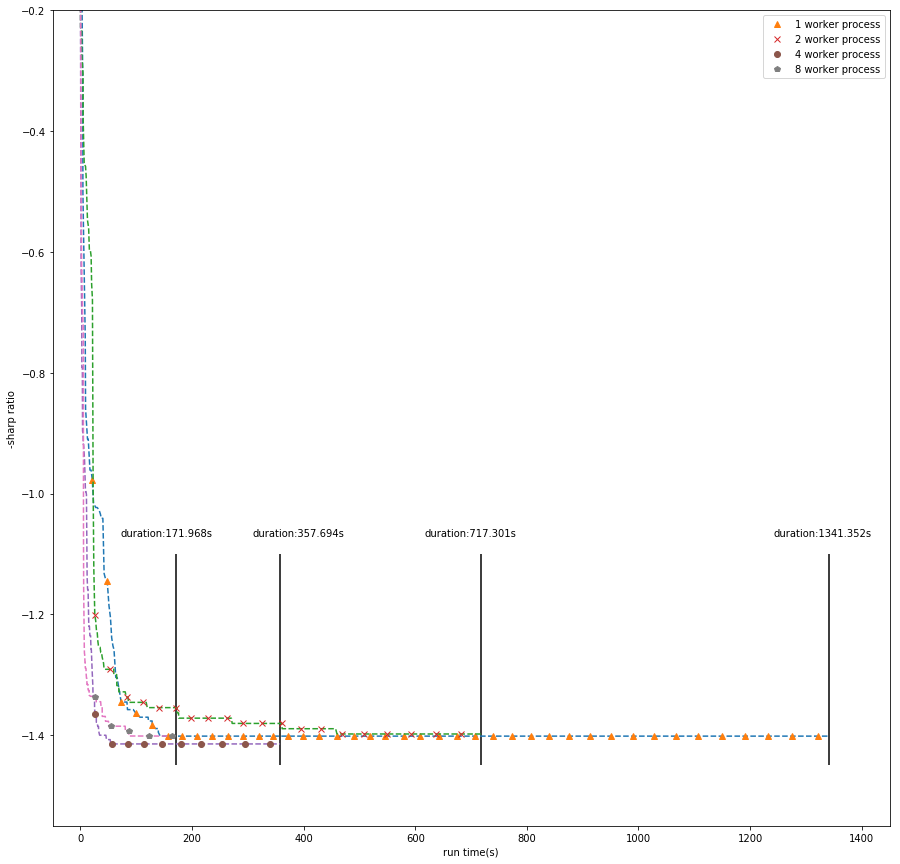
For high frequency traders, trading speed is of number 1 concern. For high frequency options trading, we can speed trading up by calculating all possible values of implied volatility (IV) for the next trading day before the market opens. When trading in real time, we just need to read the specific IV from memory instead of computing it on-the-fly. This is a huge time saver!
Off shelf, we already support standard models including the Black-Scholes for European options, Barone-Adesi-Whaley (BAW) model and the Binary Tree model for American options.
If you have a confidential option pricing model, we provide you a suite of speed-up solutions so you can keep your model private while enjoying the ultrafast calculation.
Example
On a specific date D, for the option cu1906C44000 and its corresponding underlying future cu1906, we calculate IVs at all the possible tick-by-tick combinations. For cu1906C44000, its lower bound price is 1313, and upper bound price 6083, with step size 1. We have (6083-1313)/1= 4770 possible prices. For cu1906, its lower bound price is 45310, and upper bound price 50080, with step size 10. We have (50080-45310)/10= 477 possible prices. For this pair we have 4770*477=2,275,290≈ 2 million possible IVs at all tick-by-tick combinations. For all the cu options ranging from [cu1906C44000, cu1906C54000] and [cu1906P44000, cu1906P54000], we need to calculate 35,257,455 IVs. If one can finish up each IV calculation with binary-tree method in 5s, roughly 108 hours are needed to finish all IV calculations of cu, much longer than the regular 6-hour trading period. Therefore, there is a huge demand for the speed up of the IV computation. With our HPC infrastructure and algorithms, we speed up this computation by 1000 times. The pre-caching of the IV values translates to increase in expected profit in trading. |
Level 2 stock data consist of ticks, transactions, orders, sizes and order queue information. On a daily basis, there are about 10G data produced. For back-testing and factor generation processes, people have to simulate a long period of time, say 5 years. It is very computationally demanding to calculate them. This is especially true when we often need to repeatedly go through the data. Yet, L2 data contain detailed and comprehensive information about the market. More and more people start to realize their value and to explore them. Here is where HPC comes to rescue!
Our HPC L2 Solution supports:
- Highly effective data reading and computing API.
- Computing with massive power to finish jobs that would otherwise be impossible.
- High performance yet low cost.
- High density data compression.
- Robustness from multiple instances.
- Automatic fault checking and reporting.
- APIs that support a variety of programming languages including Python, Java, C++, etc.
Example
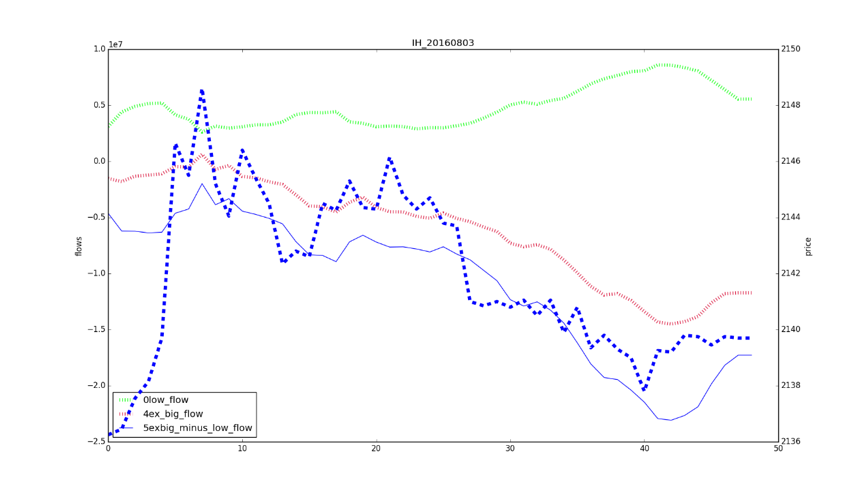
This graph is an example of calculating Money Flow factors using Level 2 transactions of Chinese HS300-index constituents. The index consists of 300 stocks in the Chinese market. The factors aggregate information of all transactions of all stocks. The computation is very heavy. Our HPC speeds it up 100+ times.